计算机访问数据经常会呈现出局部性原理,局部性原理又包括空间局部性和时间局部性。空间局部性就是说,计算机访问数据,而其存储在邻近的数据也经常会被访问。时间局部性就是说,在相对的一小段时间内,计算机经常会访问相同的数据。
关注点
- 缓存时长(复杂多维度的计算)
- 缓存失效处理(按时失效,事件失效,主动更新)
- 缓存键(Hash 和方便人工干预)
- 缓存内容及数据结构的选择
- 缓存雪崩的处理(指当缓存服务器重启或者大量缓存集中在某一个时间段失效)
- 缓存穿透的处理(指每次都缓存未命中,每次都导致一次数据库查询操作)
LRU cache
Least Recently Used(LRU) in order to achieve fast lookup and make insert/delete fast, we use queue implemented by a doubly linked list to store all the resources. Also, a hash table with resource identifier as key and address of the corresponding queue node as value is needed.
Eviction plicy
- Random Replacement (RR)
- Least frequently used (LFU)
- W-TinyLFU lfu的问题在于,过去经常使用的数据也会长期保存,为解决这问题,添加一个时间窗口
Cache concurrency
缓存的并发问题,It falls into the classic reader-writer problem,普遍的做法是加锁,显然会损失性能,一个解决办法是为缓存分区,每一分区内包含一个锁,这里还是存在热点分区上锁的频率远大于其他分区。另一个选择是使用提交日志,保存所有变更到日志,异步执行再执行所有日志,在数据库设计中是一种常见做法。
- A single transaction coordinator
- Many transaction coordinators, with an elected master via Paxos or Raft consensus algorithm
- Deletion of elements from memcached on DB updates
Distributed cache system
分布式缓存系统,主要在于调度算法,The general strategy is to keep a hash table that maps each resource to the corresponding machine Memcached.
缓存更新的套路
缓存更新的套路 Cache aside, Read through, Write through, Write behind caching
- Cache aside 在某种情况下也会出现并发问题,例如一个读操作1,缓存失效,从数据库中读,同时来了写操作2,并更新了缓存, 而读操作1回写缓存,就会造成脏数据。
- 失效:应用程序先从cache取数据,没有得到,则从数据库中取数据,成功后,放到缓存中。
- 命中:应用程序从cache中取数据,取到后返回。
- 更新:先把数据存到数据库中,成功后,再让缓存失效。
- Read through 应用认为后端就是一个单一的存储,而存储自己维护自己的cache
- Write through 不过是在更新数据时发生。当有数据更新的时候,如果没有命中缓存,直接更新数据库,然后返回。如果命中了缓存,则更新缓存,然后再由Cache自己更新数据库(这是一个同步操作)
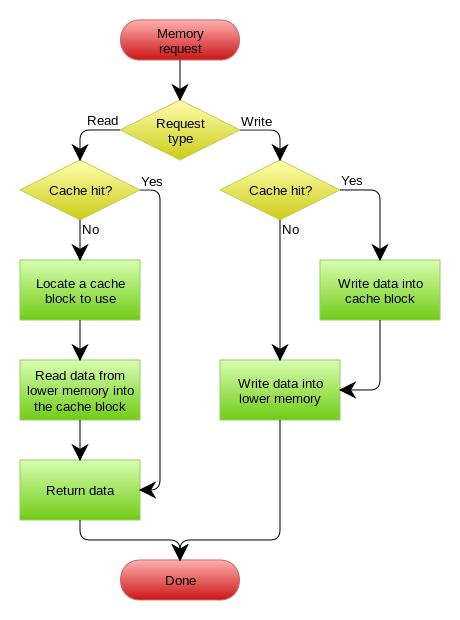
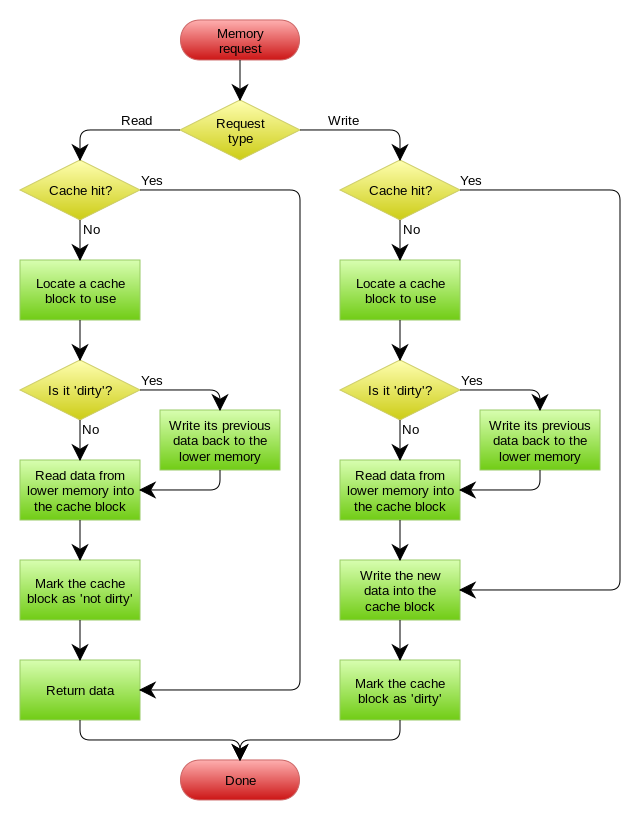
- Write behind caching 在更新数据的时候,只更新缓存,不更新数据库,而我们的缓存会异步地批量更新数据库。这个设计的好处就是让数据的I/O操作飞快无比(因为直接操作内存嘛 )
cache lib
Concurrency-safe golang caching library with expiration capabilities cache2go
concurrentcache是一款golang的内存缓存库,多Segment设计,支持不同Segment间并发写入,提高读写性能。concurrentcache
groupcache is a caching and cache-filling library, intended as a replacement for memcached in many cases.groupcache
Scaling Memcache at Facebook
Facebook采用了一系列memcached实例组成分布式memcache,基本的工作模式是:读请求首先发送给Memcache,如果请求未命中,则查询数据库,查询数据库成功后更新Memcache。写请求直接发送给数据库,成功后要删除Memcache中对应的数据。
降低延迟
利用memcache优化的原理是简单的,但是在工程实践上需要考虑更多细节,Facebook的缓存数据是分布在各个实例中的,同样请求也是并行地分配到各个实例,所以这里针对这样的情况,如何保证负载均衡、如何减少连接通讯的成本,如何控制一个memcached实例的工作量,使得其不会崩溃或者产生高延迟就是一个很重要的问题。Facebook的工程师的改进如下:
对于服务器对Memcached连接的三种操作,get, set, delete,其中get是使用UDP进行通讯,只要set和delete才是使用可靠的TCP通讯。UDP的通讯成本显著低于TCP,因为UDP不需要提前建立连接,也没有诸如拥塞控制,重连等机制。在比较良好的通讯情况下,UDP的通讯失败率(通讯失败指丢包或者乱序包)也相对较低
服务器端对收到的一堆请求进行有向拓扑图分析,选出独立的请求,将多个独立请求进行打包,进行访问。Batching也是降低成本的常见技巧。
参考资料
为了避免整个系统内进行的并发请求数过高,以及单个的实例可能成为热点,Memcache自己在连接的客户端上设置了类似TCP的拥塞控制的方法,也就是一个滑动窗口。每次只发送窗口内的请求,并逐步滑动窗口。窗口的大小和总体延迟也有重要的关系
减少负荷
所谓减少负荷(reduce load),指的是尽可能减少对数据库的访问。数据库的修改都是必须的,但是查询未必是必须的,也就是数据库查询是有可能减少的。提供Memcache处理并发请求的能力,也可以有效地减少数据库的负担。
- 租约,解决两个问题,Stale set,就是一个client拿着过期的数据往memcache里塞,第二个问题是Thundering Herd Problem.
每次cache miss,memcache会给客户端返回一个token,告诉它我这没有数据,你去取数据,取完拿这个token来更新我这的数据。如果有多个客户端同时读,同时cache miss,那么它们就会同时收到各自的token。但是,在接受数据更新的时候,比如A,B先后拿到一个token,A拿Token更新完之后,B再拿Token过来更新就不认了。如果系统收到了一个delete请求,那么啥token都不管用了
再进一步,我们可以限制发token的频率,比如每10秒最多发一个。然后对于那些拿不到token的,既然有别人去拿数据去了,何必让它们再去拿?就让它们等待一小段时间再重试。大部分时候,更新后的数据在几毫秒后就来了,它们再重试就是cache hit了。
资源池。所谓的池,指的其实是资源的分区,对于数据中的不同的访问模式,根据模式进行资源分区。例如缓存未命中的代价小,但是访问频次高的键放入一个小池,缓存未命中代价高,但访问频次低的键放入一个大池。
数据复制(Replication)最后一个降低负载的手段是在每个Pool内进行Replication。想象如下情景:我们有一台memcache机器,可以支持500K/s的请求率(request rate)。现在我们想要支持1M/s的请求,怎么办?加一台机器,然后把数据平分,两台机器一人一半
参考资料
Design a Cache System
Scaling Memcache at Facebook
Scaling Memcache in Facebook 笔记
Cache_replacement_policies
缓存穿透、缓存并发、缓存失效之思路变迁 | 并发编程网 – ifeve.com
从0到100——知乎架构变迁史
如何设计redis缓存点赞数据
https://redis.io/topics/twitter-clone
Redis使用最佳实践 | dslztx
微博关系服务与Redis的故事
缓存更新的套路 | | 酷 壳 - CoolShell
Using Redis at Pinterest for Billions of Relationships
【第135期 Redis 11种应用场景
Redis几个认识误区 – 后端技术 by Tim Yang
Facebook and memcached - Tech Talk - YouTube
Facebook 对 Memcache 伸缩性的增强 - 技术翻译 - 开源中国社区
缓存那些事 -
缓存一致性(Cache Coherency)入门
缓存方案如何设计才能切合业务需求? - 知乎
Le Cloud Blog
Redis 高可用架构最佳实践 | 温国兵的随想录
https://content.pivotal.io/blog/using-redis-at-pinterest-for-billions-of-relationships
解剖Twitter:Twitter系统架构设计分析 | 互联网的那点事
使用多个HashSet存储,key为gameID value为userID set集合
关注游戏,取消关注,获取某游戏下关注的人,获取某人关注的所有游戏
分布式系统缓存设计浅析 - lengyuhong - 博客园
如何设计API的限流(Rate Limit)功能:4种类型限流器图解
高可用服务限频与降级那些事儿 上 | 峰云就她了
如何用redis/memcache做Mysql缓存层?
面对缓存,有哪些问题需要思考?
缓存方案如何设计才能切合业务需求?
Why-does-Facebook-use-delete-to-remove-the-key-value-pair-in-Memcached-instead-of-updating-the-Memcached-during-write-request-to-the-backend