The Log
有一段时间被一篇称为学习笔记:The Log(我所读过的最好的一篇分布式技术文章)所刷屏,各大技术文章推荐APP和微信都推荐了这篇文章,来自于LinkedIn关于kafka的文章,核心如题—The Log。(你可以把这节看成对这篇文章的缩减)
(一)log由来、重要性、应用
对于任何一项新技术都会先抛出三个问题what?why?how?。首先log是记录何时发生了什么,这里主要要与普通应用日志所区分开来,log是更大范围的数据记录。它是分布式数据系统和实时计算系统的核心,在数据库中log主要保证数据的ACID,面向机器的log同样也可以用在
– 消息系统
– 数据流(data flow)
– 实时计算
在分布式系统中主要解决两个很重要的分布式数据系统中的问题:1) 有序的数据变化,2) 数据分布式化,一般来讲日志会分为物理日志:实际内容发生的变化,逻辑日志:对数据所有操作的日志。在分布式中应用分为
1) State machine model(active – active)
2) Primary-back model (active – passive)
如下图所示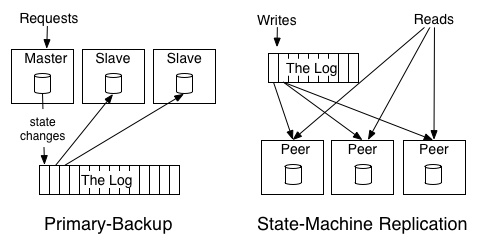
(二)数据集成(log如何扮演中间人作用)
所谓数据集成,就是将一个组织中的所有服务和系统的数据,变得可用。数据集成的主要问题在于如何集成事件数据或者说应用日志数据。日志是具有结构性的,这意味着log在数据源和订阅者之间充当管家的职能,看到这可能有人会问消息系统不也可以这样做吗,之所以分开来讨论,是因为它们之间保持的特性不同,消息系统更重要的是在系统间传递有效信息。而log则提供了持久性保证以及强有序的语义,这点在通讯系统中,称为原子广播。消息系统+log=kafka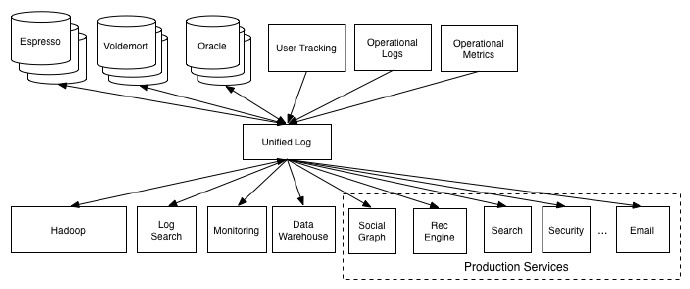
(三)事件与log有效应用(log的具体优势)
在众多事件响应中我们需要以log为核心的架构实现无耦合的、事件驱动的系统,通过离线处理事件,利用log的结构化数据,我们可以在这基础上构建搜索、实时监控、实时报警等等,因为从log出来的数据是干净和规范的。log在流处理方面主要有两方面目的
1) 保证了数据集可以支持多个订阅者模式,及有序。
2) 可以作为应用的缓冲区。这点很重要,在非同步的数据处理进程中,如果上游的生产者出数据的速度更快,消费者的速度跟不上,这种情况下,要么使处理进程阻塞,要么引入缓冲区,要么丢弃数据或阻塞处理。
(四)扩展性和log合并回收处理(log如何解决难点)
扩展性主要通过下面三个方面来实现
1) 对log进行分割(partitioning the log)
2) 通过批量读写优化吞吐量(将小的读写log组成更大的、高吞吐量操作)
3) 避免不必要的数据拷贝 零拷贝数据传输技术(zero-copy data transfer)
Kafka使用了log合并或者log垃圾回收技术:
1)对于事件数据,kafka只保留一个时间窗口(可在时间上配置为几天,或者按空间来配置)
2)对于keyed update,kafka采用压缩技术。此类log,可以用来在另外的系统中通过重放技术来重建源系统的状态。
(五)从log角度如何看待分布式系统(系统构建)
log在任何系统中都扮演着下列角色
1:抽象数据流,2:保持数据一致性,3:提供数据恢复能力
你可以将整个机构中的应用系统和数据流,看作是一个单独的分布式数据库。
将面向查询的独立系统,比如Redis , SOLR , Hive tables 等等,看作是一种特别的、数据之上的索引。
将Storm、Samza等流处理系统,看做一种精心设计过的触发器或者物化视图机制。
log的出现主要是解决以下问题
1) 处理数据一致性问题。无论是立即一致性还是最终一致性,都可以通过序列化对于节点的并发操作来达到。
2) 在节点间提供数据复制。
3) 提供“提交”的语义。比如,在你认为你的写操作不会丢失的情况下进行操作确认。
4) 提供外部系统可订阅的数据源(feeds)。
5) 当节点因失败而丢失数据时,提供恢复的能力,或者重新构建新的复制节点。
6) 处理节点间的负载均衡。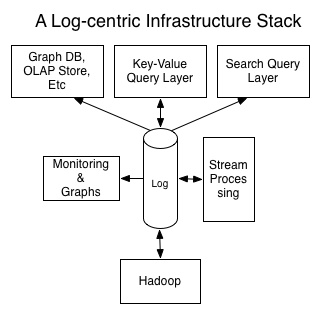
显然,一个以log为核心的分布式系统,其本身立即成为了可对其它系统提供数据装载支持及数据流处理的角色。同样的,一个流处理系统,也可以同时消费多个数据流,并通过对这些数据流进行索引然后输出的另一个系统,来对外提供服务。
基于log层和服务层来构建系统,使得查询相关的因素与系统的可用性、一致性等因素解耦。
(六)总结
这篇文章主要讲了log在分布式系统的应用,kafka这个框架则是融合了消息系统和log。所有的这些我们可以看出分布式系统朝着数据基础设施被离散为一组服务,以及面向应用的系统API,从LinkedIn的Java技术栈可以看出
– ZooKeeper:解决分布式系统的同步、协作问题(也可能受益于更高抽象层次的组件如helix、curator).
– Mesos、YARN:解决虚拟化和资源管理问题。
– 嵌入式的组件Lucene、LevelDB:解决索引问题。
– Netty、Jetty及更高抽象层次的Finagle、rest.li解决远程通讯问题。
– Avro、Protocol Buffers、Thrift及umpteen zlin:解决序列化问题。
– Kafka、bookeeper:提供backing log能力。
参考资料
1.学习笔记:The Log(我所读过的最好的一篇分布式技术文章)kafka, log, 分布式, 数据库
2.log:每个工程师都应该知道实时数据的统一抽象源文,出自LinkedIn