概述
在开源中国闲逛时发现了这个项目-众推,是一个以Hadoop分布思想为基础类今日头条的开源项目。虽然该项目将去重过滤、文本分类单独出来,但是我认为这都属于数据处理部分。所以我将整个项目的核心划分为三个部分:分布式爬虫、数据清洗与处理、web工程。分别也对应了数据的采集、处理和展示。该项目没有继续下去,可能是因为这个项目不够吸引人,创意不是很好,但是我认为这个项目是当前所有互联网项目技术架构的通用骨架,而本人也正在恶补分布式、机器学习等知识,也想拿Python写一个项目练手,所以就有这个项目,这个项目还处于资料收集、技术储备阶段,这个阶段会有一系列的demo。
关于系统架构
SOA面向服务架构大概是现在架构的通用标准,这种架构的最大优势在于高内聚、低耦合,在UNIX的设计思想中也体现了这一点。SOA在我看来就是模块化,而模块之间的通信则是通过RPC或者消息系统,以我现在的理解,将RPC用在模块内的通信,而消息系统则用在不同模块之间,以下是项目的初略架构图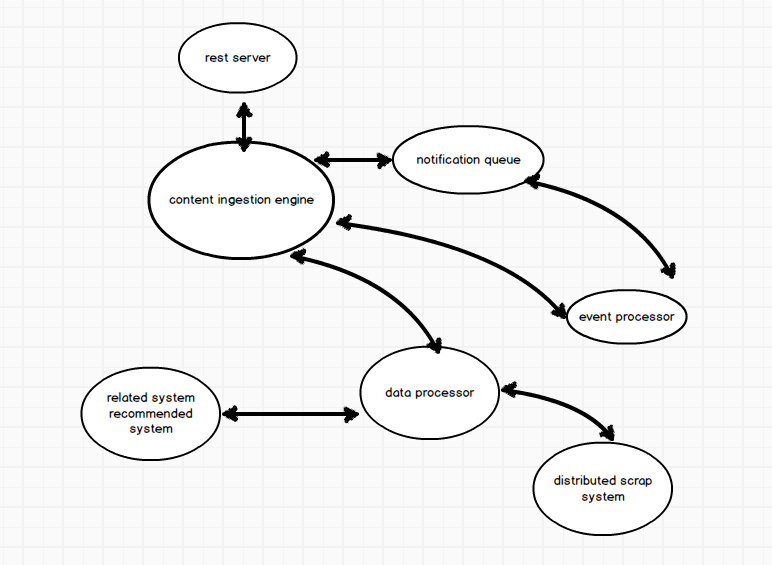
分布式爬虫部分
网络爬虫的基本工作原理: 1)从一个初始URL集合中挑选一个URL,下载该URL对应的页面;
2)解析该页面,从该页面中抽取出其包含的URL集合,接下来将抽取的URL集合再添加到初始URL集合中;
3)重复前两个过程,直到爬虫达到某种停止标准为止。
爬虫中需要重点关注的问题:
1)判断要爬取的URL是否爬过,判重使用Bloom Filter,它可以使用固定的内存(不随url的数量而增长)以O(1)的效率判定url是否已经在set中。但是如果这个url不在set中,BF可以100%确定这个url没有看过。但是如果这个url在set中,它会告诉你:这个url应该已经出现过,不过我有2%的不确定性。
2)分布式爬取(维护分布式队列)
我们把这100台中的99台运算能力较小的机器叫作slave,另外一台较大的机器叫作master,那么回顾上面代码中的url_queue,如果我们能把这个queue放到这台master机器上,所有的slave都可以通过网络跟master联通,每当一个slave完成下载一个网页,就向master请求一个新的网页来抓取。而每次slave新抓到一个网页,就把这个网页上所有的链接送到master的queue里去。同样,bloom filter也放到master上,但是现在master只发送确定没有被访问过的url给slave。Bloom Filter放到master的内存里,而被访问过的url放到运行在master上的Redis里,这样保证所有操作都是O(1)。
主要参考Fourinone国产四不像的分布式模型。
数据处理部分
数据的存储采用纯文本模型,索引项格式为
页面号码|页面大小|URL文本大小|抓取时间文本大小|URL文本|抓取时间文本
web工程部分
结语
参考资料
1. scrapy-redis,作者:廖雪峰Redis-based components for scrapy that allows distributed crawling
2. 如何入门Python爬虫
2. distribute_crawler使用scrapy,redis, mongodb,graphite实现的一个分布式网络爬虫,底层存储mongodb集群,分布式使用redis实现, 爬虫状态显示使用graphite实现。